
Sep 7, 2021
External vs. internal automatic database tuning approaches
Andy Pavlo

Databases expose many configuration parameters (or “knobs”) that allow you to change the system’s runtime behavior. Correctly tuning these knobs is key to good application performance and efficiency, but it’s a complex task because of the many possible choices that one has to make. What settings to use for your database depends on many factors: what the queries are, how big the database is, what the application is, and what the hardware is.
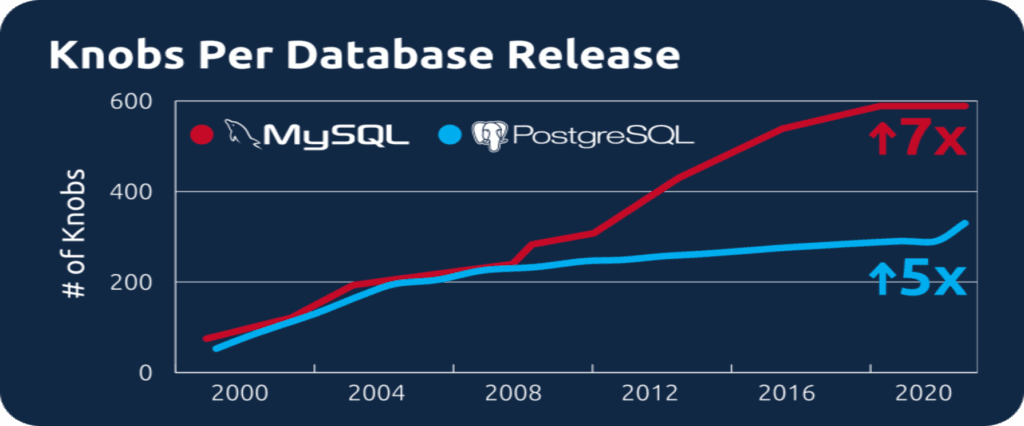
These systems have gotten harder to tune over time too. For example, in the last 20 years, MySQL and PostgreSQL have increased the number of knobs that they expose to tune by 7x and 5x, respectively.
This increased complexity has led to the development of machine learning (ML) approaches to automatically tuning database management systems (DBMSs). Commercial examples include Oracle Autonomous Database and OtterTune, as well as academic research projects like our NoisePage project at Carnegie Mellon.
Machine-learning approaches to automatic database tuning fall into two categories: external tuning and internal tuning. As we now discuss, both have their pros and cons.
External Database Automation
An external ML approach is when the tuning algorithm can only observe the target’s inputs and outputs in its decision making process; the algorithm has no knowledge of the system’s internal structure, design, or implementation. In the context of database tuning, an external tuning tool interacts with the DBMS only through its standard APIs (e.g., SQL) and monitoring services (e.g., Amazon CloudWatch). In other words, an external ML approach does not require changes to the DBMS’s source code, nor does it need the user to install custom extensions.
OtterTune is an external tuning service; it uses the target DBMS’s standard interfaces (SQL) to:
Retrieve the database’s current configuration and other runtime info (e.g., metrics),
Change the configuration, and
Restart the system if necessary.
OtterTune implements an exteranl tuning ML algorithm to improve a database’s query performance and efficiency without needing to modify the DBMS nor examine the application’s queries and data.
Internal Database Automation
An internal ML approach is when the DBMS has automatic tuning components tightly integrated into its internal architecture. Such integration requires the system developers to add “hooks” in the DBMS’s source code to retrieve telemetry data and modify its behavior. With the former, these changes could allow the tuning algorithms to collect information about the system’s runtime behavior and low-level hardware measurements, such as the number of CPU cycles used to insert a single record into an index.
The algorithms could then control the system’s behavior in ways that are not possible through existing APIs. For example, the tuning algorithm could make adjustments to the DBMS at the session-level to affect how the system executes individual transactions or queries. Such fine-grained control is not possible by humans and is not feasible with existing approaches today.
Which approach is better?
In external tuning automation systems like OtterTune, the ML logic exists outside of the DBMS. Thus, one can adapt the service to support new databases or new database versions more easily than with internal ML approaches. For example, we extended OtterTune to support Oracle within a few weeks for our deployment at Societe Generale. External tuning is also usable when it is not feasible to modify or extend a database or modify application code. For example, Amazon does not allow users to change the database’s system binary for their MySQL or PostgreSQL RDS instances. Instead, they only allow a limited number of extensions.
Internal tuning automation technology is still nascent. Developing ML-driven internal tuning requires deep knowledge of the system internals and source code, so DBMS users will have to wait for their vendors to add the capabilities to their database–and then upgrade to the new version of the DBMS. It is going to take a long time for every DBMS to incorporate internal ML optimizations because these changes are custom code specific to the system; one cannot easily port them to a new database. Other than Oracle Autonomous Database, Oracle’s MySQL Heatwave Autopilot, Huawei’s OpenGauss, and our work with CMU’s NoisePage, internal DBMS automation tuning implementations are not common today.
How will these become part of your infrastructure?
ML algorithms, whether external or internal to the database, automate the complex database tuning process. Automated tuning makes it easier to configure, optimize, and maintain a complex database deployment. This reduces the need to have developers and administrators “babysit” the database to make sure that it is performing its best. Those people can instead spend their time working on more fulfilling activities, like application development and other tasks that cannot be automated.
Automated tuning is an essential tool for anyone who cares about database price-performance, but does not have the time or expertise to keep multiple databases tuned for optimal performance.
A Final Word
Given today’s extreme reliance on databases, everyone stands to benefit tremendously from advancements in the field of automated tuning using ML. Internal and external approaches have their trade-offs. It is exciting to see researchers and the industry as a whole are making advancements in creating autonomous databases, with ML doing the heavy lifting.
In deployments of OtterTune, we have seen it achieve significant performance improvements and cost reductions for PostgreSQL and MySQL database instances versus both default configuration settings (view the benchmarks) and human-tuned configurations.
Summary of Pros & Cons
External ML approaches
Pro: More generic solution (portable across DBMS systems, hardware).
Pro: Simpler to design and build since you do not need to understand the DBMS internals.
Con: Lack of explainability on the ML algorithm’s decision making.
Internal ML approaches
Pro: Potentially need less data to achieve good results compared to black box approaches.
Pro: Fine-grained control over the DBMS’s telemetry and runtime behavior.
Con: Higher engineering cost for DBMS developers.
Con: Lack of portability: ML algorithms are designed for only that system.


