
Jul 19, 2021
Seven years of OtterTune R&D: Part 1 – The lab years
OtterTune Team

In 2013, Andy Pavlo started the OtterTune research project at Carnegie Mellon University (CMU) as an extension to the OLTP-Bench project. Recognizing the importance and complexity of DBMS configuration tuning, The National Science Foundation (NSF) funded the project with a $500K grant in 2014. That same year, Dana Van Aken, who is now our co-founder and CTO, started as a new PhD student. She became the primary researcher for the project.
For the next seven years, we worked on the research that led to the commercial release of OtterTune this past May. The insights of our work have been published in several peer-reviewed papers. In a pair of blog posts, we’ll share an account of the research and findings that led us to where we are today.
Here are some of the highlights and lessons we learned during the early years, developing OtterTune’s machine learning algorithms and services architecture.
Reusing training data to improve the effficacy of tuning recommendations
The first paper about the OtterTune service, presented at SIGMOD in 2017, was Automatic Database Management System Tuning Through Large-scale Machine Learning.
The paper covered our automated, machine learning-driven approach, leveraging past experience and collecting new information to tune DBMS configurations. In our research, we used a combination of supervised and unsupervised machine learning methods to:
Select the most impactful knobs,
Map unseen database workloads to previous workloads so we can transfer experience, and
Recommend knob settings.
We implemented our techniques in OtterTune and tested it on three DBMSs. Our evaluation showed that OtterTune recommends configurations that are as good as or better than ones generated by existing tools or a human expert.
We designed OtterTune to use a pipeline of different machine learning algorithms (purple shapes in the diagram below) to: 1) characterize the target database’s workload, 2) identify which knobs to tune, and 3) recommend new configuration settings. The OtterTune service uses ML metrics to map a new database workload it’s trying to optimize to a similar workload that the service has seen in the past. This is how OtterTune can reuse training data it has collected from tuning other databases to improve the efficacy of its recommendations.
The OtterTune machine learning pipeline:
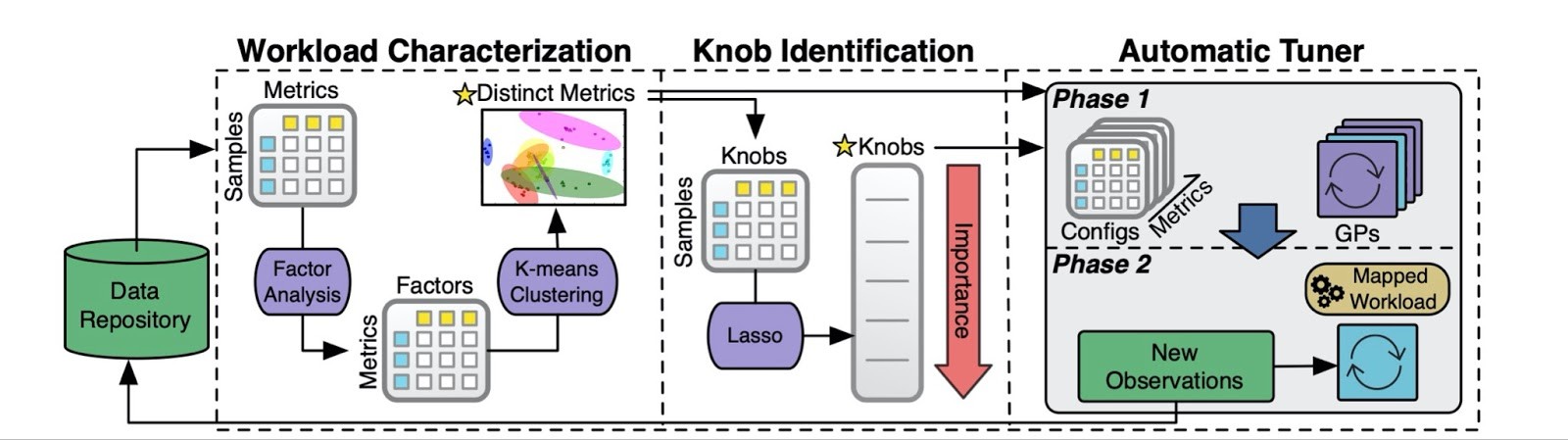
Key learnings and advancements
For this research, we ran 100,000 trials to build the initial training data corpus for OtterTune. Each trial was benchmarked using OLTP-Bench. As our ML algorithms improved, we found that we did not need to collect as much training data.
Among other ML algorithms, OtterTune uses a Gaussian Process Regression algorithm, a common approach for solving black-box optimization problems and hyperparameter tuning. We originally wrote the algorithm in MATLAB. During a summer internship at CMU, Bohan Zhang, one of OtterTune’s co-founders, then rewrote it in TensorFlow and improved its computing efficiency, resulting in a 5x performance increase.
The first version of OtterTune supported MySQL, PostgreSQL, and Actian Vector. We evaluated both OLTP and OLAP workloads. We were using the latest versions of MySQL (v5.6) and PostgreSQL (v9.3) at the time, and we learned that the earlier DBMS versions had fewer knobs for improving performance of OLAP workloads than OLTP workloads.
OtterTune was well-received in academia after presenting it at SIGMOD 2017, but it wasn’t until we were invited to write a guest post for the AWS Machine Learning blog that we started hearing from a lot of industry folks trying to solve similar problems.
Automatically selecting a configuration that improves DBMS performance
A year later, we presented a short paper, A Demonstration of the OtterTune Automatic Database Management System Tuning Service, at the VLDB conference in Brazil.
The paper described OtterTune’s microservice architecture. The tuning agent (now called the Driver) was used to collect the target DBMS’s current configuration and metrics and then transmit them to the OtterTune tuning manager. The tuning manager stored this data in its internal repository of previous tuning sessions. The algorithm then trains models with the data from the target DBMS as well as previous tuning data from similar workloads to produce a new configuration recommendation. The tuning manager sent this new configuration back to the agent to install on the target DBMS.
Key learnings and advancements
For the live demonstration at VLDB, we challenged conference attendees to tune PostgreSQL (v9.6) running the TPC-C benchmark and compared them against OtterTune’s tuning algorithm. We gave them a web interface that allowed them to set the values for several knobs and then ran the workload.
OtterTune was able to get 20% better performance than the best configuration from a human.

Bohan Zhang in action at VLDB 2018. View other VLDB 2018 photos.


