
Aug 30, 2022
Fixing slow PostgreSQL queries: How to make a smart optimizer more stupid
Haonan Wang | Bohan Zhang

Ah, the frustrating slow-running PostgreSQL query. What’s an otter to do?
The first thing to do — without question — is run ANALYZE. PostgreSQL’s ANALYZE command collects statistics about specific table columns, entire tables, or entire databases and stores the results in the pg_statistic system catalog. PostgreSQL’s query planner then uses these statistics to help determine the most efficient execution plans for queries.
We have found that running ANALYZE more frequently has solved many of our customers’ slow query problems. It’s like the “restart your computer when it gets slow” advice for databases. OtterTune has a health check in place to determine if ANALYZE needs to be run more often.
But what if running ANALYZE doesn’t provide the necessary improvement? A recent interaction with an OtterTune user might shed light on your issue.
When good optimizers go bad
Recently, a Postgres user contacted us via the OtterTune Community Slack channel. This OtterTune user reported that a query ran slowly when using ORDER BY along with the LIMIT 10 clause. This LIMIT will cause us problems later in this article, which is why we are calling it out.
This is a common query pattern in many applications to show the top n entries in a table (e.g., the most recent orders for a customer). In this case, the application retrieves the first ten items from a set named ‘ABC.’ But the customer reported that the query took an inexplicably long time to complete (18 seconds!).
OtterTune’s automated health checks initially recommended that the customer to increase statistics collection on the table (i.e., ANALYZE) by increasing PostgreSQL’s statistics_target configuration knob. But while this recommendation made other queries run faster, it did not help this problem.
There are several StackOverflow posts with others that have similar issues in PostgreSQL queries that use LIMIT clauses with ORDER BY (Example 1, Example 2, Example 3). See also this Carnegie Mellon Database Tech Talk from a leading PostgreSQL developer that discusses this exact problem (starts at 45:15). So this problem is not unique to our customer.
Our engineers worked with the customer to get the query’s execution plan using EXPLAIN ANALYZE. We then use Dalibo’s fantastic visualization tool to examine the plan to understand what is going wrong. In the visualization shown here, we see that PostgreSQL’s optimizer overestimates the number of tuples that it expects the nested-loop join operator to emit by almost 1000x. This causes it use an index scan on the item table’s primary key index (item.id) for the outer table (i.e., the child operator on the left side of the join).
Using this index will automatically sort the item tuples in the same order needed in the query’s ORDER BY clause. The optimizer is trying to be clever here: it knows that there is an LIMIT operator above the join, so rather than sort the thousands of tuples that it expects from the join to only grab the first ten tuples, it uses the item table’s index to get the data pre-sorted.
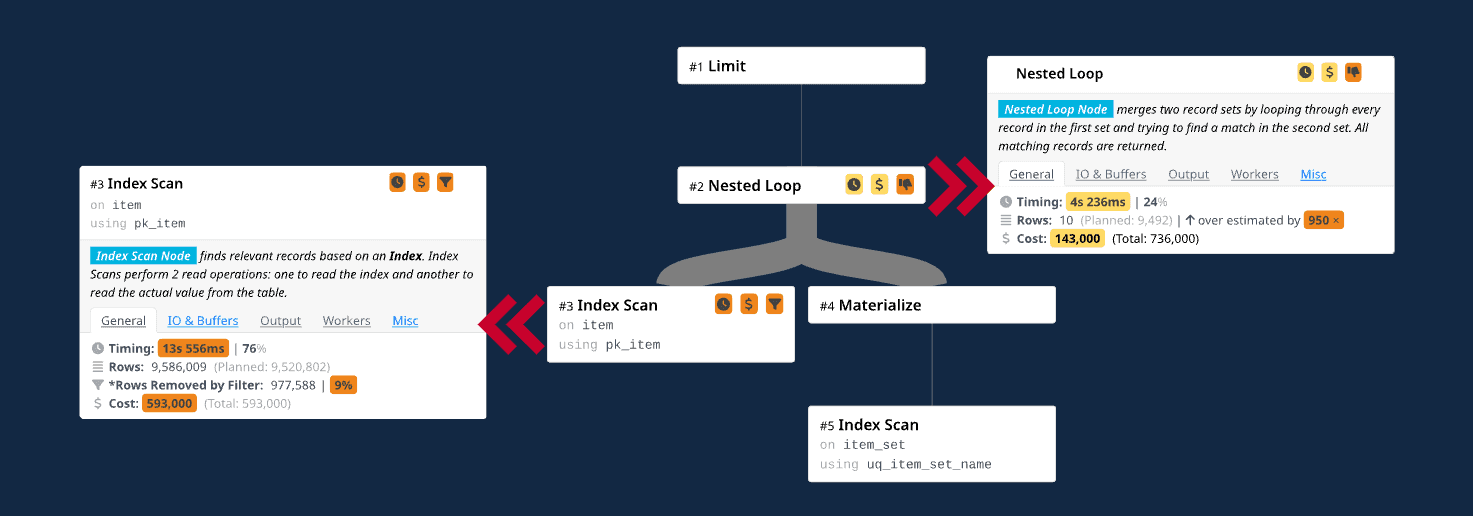
Original query plan with the ORDER BY and LIMIT clauses. Execution Time: 18 seconds.
The problem is that the DBMS does not know where the rows are located physically in the item index that will satisfy the predicate item_set.name = 'ABC' on the other side of the join operator. The DBMS thinks it will be only ten rows, but it ends up being 9400! Notice how it almost correctly estimates the number of rows it will retrieve from the index scan on the item table. This would not have been a big deal if the DBMS’s assumption that it could cut off the scan after the first ten rows were correct.
LIMIT is ruining my life
On a lark, we decided to try the SQL query again, but this time without the LIMIT clause since that seems to be the source of the problem. To our surprise, the query finished in 0.085 ms! This is a massive 99.9995% reduction. Of course, we were initially suspicious, as one can often make mistakes when running experiments that can lead to erroneous results.
We ran the query several times more, and the result was always about the same. As you can see in the visualization below, the new query plan switches the order of the tables for the join operator:
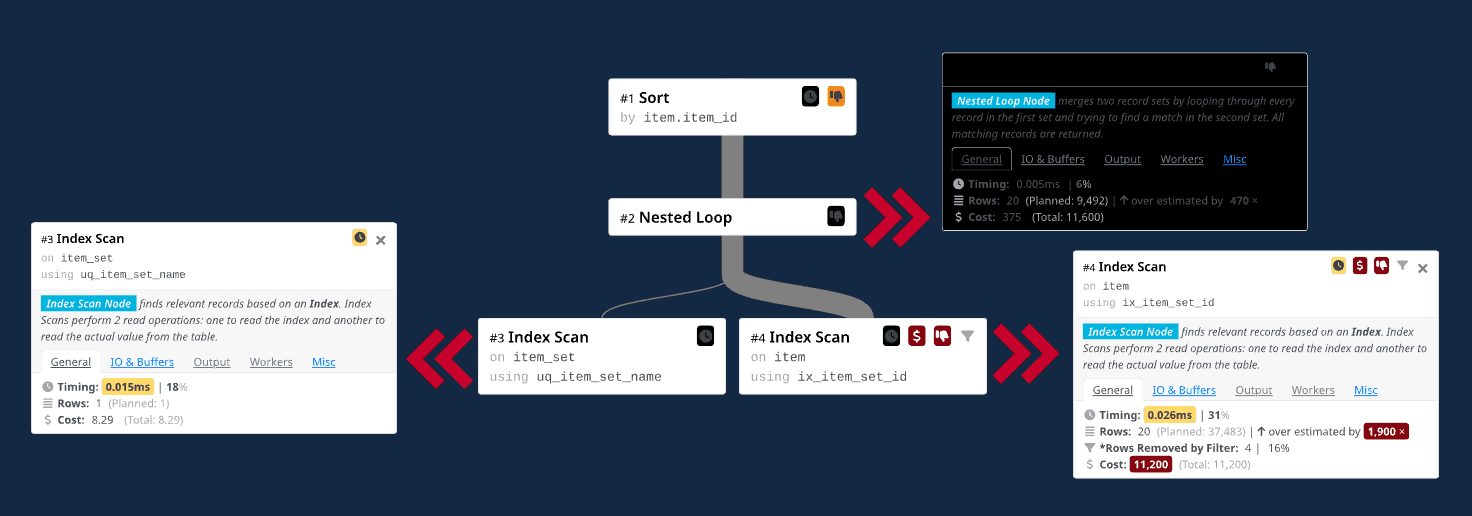
Updated query plan after removing the LIMIT clause. Execution Time: 0.085 ms.
The question we then had to figure out was what PostgreSQL is doing here that would cause such a dramatic performance difference when we remove the LIMIT clause. Well, once again, it has to do with the optimizer mispredicting how many rows it will access. The outer table for the join operator is now an index scan on the item_set table using a unique index on its name field.
Because the index is unique, we know it will return at most one item_set row. Now there is a single probe into an index on the item table’s item_set_id field for the join’s inner table that feeds into the sort operator.
The crux of the problem is that we want the join ordering in the plan that PostgreSQL generates in the query without the LIMIT but still keep the LIMIT. The customer could have modified the application code to just do truncation itself, but that seems wrong. And we’re database people, after all, and this kind of problem should be solved without having to modify the application code.
It also can cause problems in the future if the assumptions we make now about the query change. For example, the query only returns 20 rows right now, but what happens if the database changes and now the query returns 1 million rows?
PostgreSQL hints without hints
One way to solve this problem is to add hints to the query to tell the optimizer the right way to join these two tables. But PostgreSQL famously does not support plan hints (at least not natively — you have to install pg_hint_plan). In our example, the customer did not have the necessary permissions to install this extension in RDS, and the person who could do it was on vacation.
We needed another way to trick the optimizer into not picking the item table’s primary key index. To do this, we can rely on two important facts about PostgreSQL’s optimizer implementation. The first is it does not resolve arbitrary expressions in ORDER BY clauses before execution. For example, if you use the expression ORDER BY a + 0 (where attribute a is an integer), it does not infer that it can rewrite a + 0 into just a.
The second fact about PostgreSQL’s optimizer is that it looks for exact key matches when identifying whether it can use an index to access a table to remove the need to add an additional Sort operator (we can ignore prefix searches for now). In the case of the item.id index for our example, unless the ORDER BY clause contains the same columns as the index, then it will always include the Sort operator in the query plan.
Putting these two ideas together, we can fake out PostgreSQL’s optimizer into not using the item.id index by changing the ORDER BY clause to be item.id + 0:
As humans, we know that item.id + 0 and item.id are semantically the same, but PostgreSQL isn’t clever enough to figure that out. Interestingly the optimizer decides to perform a sequential scan on the item_set table instead of using the unique index on the name attribute. Other than that, the new query plan is essentially the same as the one without the LIMIT (i.e., it joins the tables in the right order).
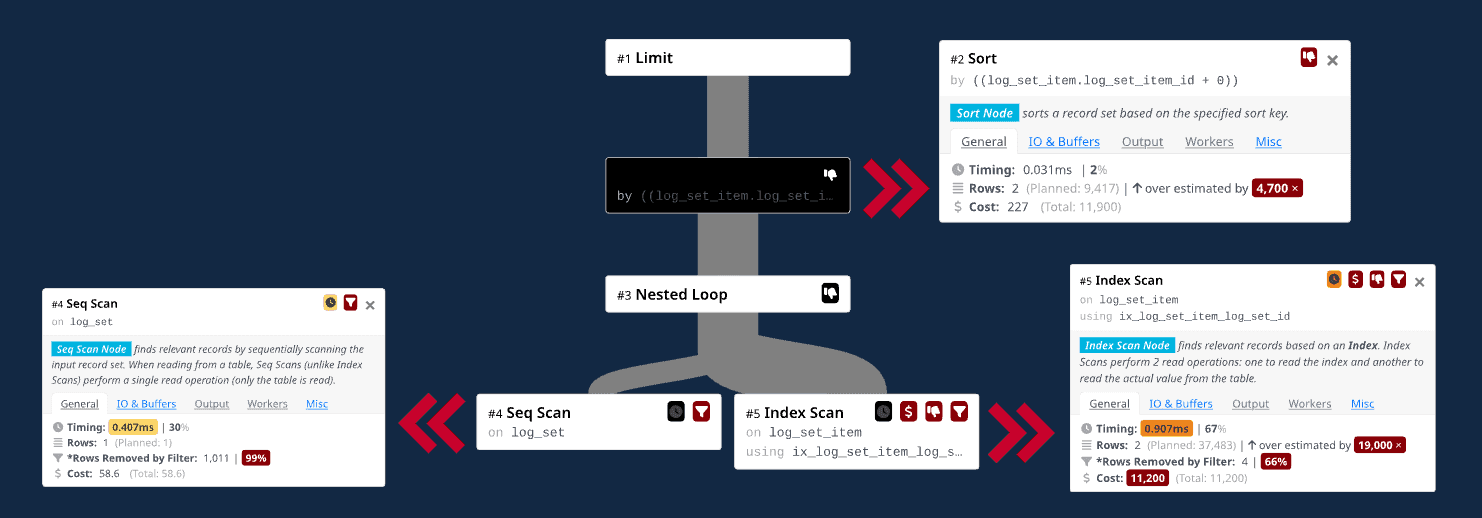
Final query plan using the ORDER BY trick. Execution Time: 1.39 ms.
The execution time for this new query is 1.39 ms. This was not as good as the 0.085 ms execution time when removing the LIMIT clause entirely, but the customer was happy because the new query is still 10,000x faster than before.
The future of OtterTune
We are here to help suss out issues like this and help databases work better. The above problem exemplifies where we are going next with OtterTune. Although automated configuration tuning is critical as it greatly benefits database performance and efficiency, if the DBMS still chooses crappy query plans, then all our efforts are for naught.
OtterTune’s machine learning algorithms continue to evolve, and we are working on ways to provide additional automated solutions. We are building out the next version of OtterTune that will start to tackle these exact kinds of problems for MySQL and PostgreSQL. In the meantime, reach out to us via our Slack channel. We’re here to help.


